
Demystifying data: The hidden foundation behind generative AI success
Creating applications using large language models is just the tip of the iceberg for realizing your generative AI ambitions. Below the surface, these applications require carefully curated data foundations to ensure safety, accuracy and inclusivity.

Generative AI promises to help organizations, including businesses, government agencies and academic institutions, transform operations and create innovative new services. For those that get it right, the advantages are undeniable. According to AWS Enterprise Strategist Helena Yin Koeppl, the benefits can be found mainly in these areas:
- New, innovative ways of engaging with customers and employees
- Increased productivity, in areas such as coding and back-office operations
- Extracting meaningful insights from company databases, at light speed
- Creating new content for marketing campaigns, blog posts and corporate reports
- Research and development in specialized fields


But successfully implementing generative AI requires careful vetting, preparation and management of the vast amounts of data required to drive foundation models. Indeed, the output is merely the tip of the iceberg – the data foundation that lies below is just as important.
In the AI era, an organization’s data is more critical than ever. It’s a differentiator that can add personalization and context for customers, taking services and experiences to the next level. But it must be managed carefully. AI that’s informed by low quality or incomplete data can cause considerable damage – to the organization, its customers and to society as it makes its way into sensitive areas like healthcare and security.
“You have a foundational, societal responsibility to get this right,” says Tom Godden, Director, Enterprise Strategy at AWS. Indeed, if not built on data that’s been carefully vetted, generative AI can yield false or even dangerous information, pose legal and security risks and reinforce harmful biases.
From awareness to action
Ninety-three percent of chief data officers agree that a robust data strategy is crucial for getting value from generative AI, but a full 57 percent say they have yet to build one, according to a recent survey published by AWS. So where should they begin?

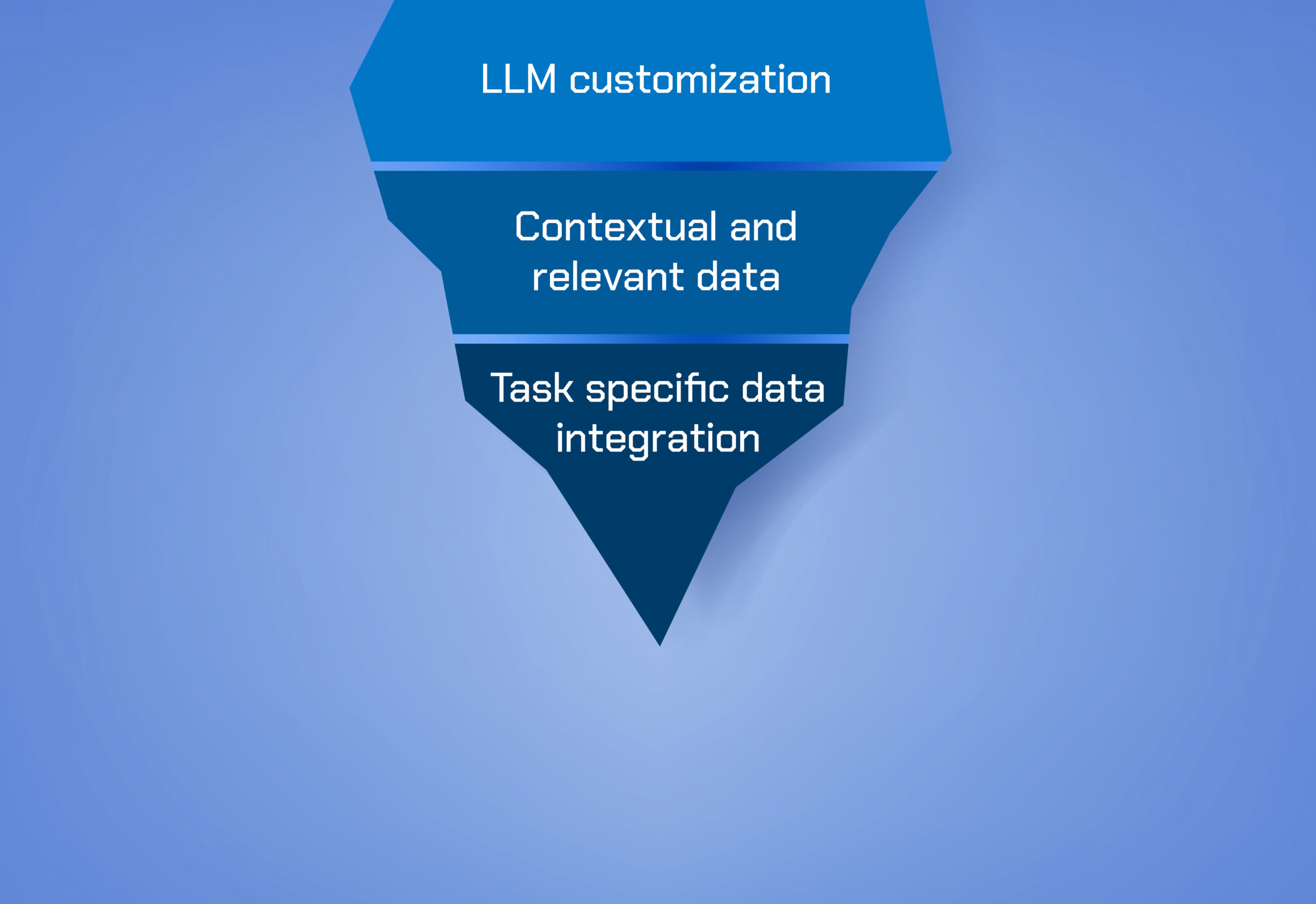
Enterprises must first decide whether to use a publicly available large language model (LLM) as is, or to create a customized version. AWS believes that at least some customization is worth the effort, as it will yield more relevant information, provide more accurate answers for stakeholders and reduce bias. “We strongly advise organizations to leverage their own data to make the foundation models more customized to their use cases with techniques like Retrieval Augmented Generation (RAG) or fine tuning,” says Koeppl.
Godden adds that custom models typically perform better. “We are seeing organizations begin to explore and experiment with more bespoke foundation models that are targeted to their data and their use cases. And it isn’t just that they’re bespoke, they’re more task specific, and it’s allowing them to be more focused and improve their performance and accuracy.”
What “good data” looks like
To move forward with generative AI, organizations must also develop a robust data governance strategy. This includes establishing processes for ensuring data quality, availability, diversity and security.
Ensuring quality can start with documenting data in clear and comprehensible ways. Specific assets can be tagged as trusted or compliant, meaning that they come from a verified source, are accurate, consistent and safe to use in an LLM. “In other words, it has high value,” says Godden. “It has the Good Housekeeping seal of approval.”
The information must be kept up to date through good governance. Godden recounts his time working with a health insurer that had historical data that advised people under stress to take up smoking. “We have to be careful with the data we’re putting into these things,” says Godden.
Availability means freeing data from silos and making it widely accessible throughout an enterprise. Limiting access to data can limit innovation, according to Godden. “It’s common for organizations to lock their data away and have everyone make a use case for why they need it,” he says. “Instead, you have to ask, ‘Why wouldn’t I share this data?’”
Diversity means ensuring that the data is representative of an organization’s entire customer or user base and not culled from sources that will perpetuate biases. This is particularly important in areas that have been prone to discrimination, such as lending and hiring. “You need to make sure that you don’t have implicit biases in your training data that are perpetuated into a model, or even explicit ones,” says Godden.
To that end, data sets should be inclusive. To achieve this, organizations must curate data from a wide range of trusted sources. For some use cases, a truly representative model should, for example, be able to recognize and respond to diverse language dialects. Responses must be “culturally relevant and linguistically relevant to your user base,” says Godden. Having diverse teams work on AI projects can help to fill gaps in the data, according to Godden. “A multidisciplinary team with diverse backgrounds will provide you with invaluable inputs.”
A robust data strategy must also address security. Generative AI poses unique challenges in this area, given the huge volumes of data involved. Just training publicly available LLMs on internal data can potentially expose that data to the wider world. “You need to ensure that there is no data leaking and there is no danger of a data security breach,” says Koeppl. At the very least, organizations should encrypt and anonymize data to protect individuals’ privacy in the event of a breach and also to maintain compliance with privacy rules such as the General Data Protection Regulation (GDPR).
Expert review
Finally, before putting an AI solution into market, enterprises must stress test the product to ensure it can handle the rigors of daily use. “You want to make sure you’ve reached the threshold you want to reach before you launch,” says Koeppl.
Even then, experts should review the final output in highly specialized fields like law or healthcare, where mistakes can have dire consequences. For all its progress, generative AI is occasionally prone to “hallucinations” that yield inaccuracies. “Sometimes the result sounds very plausible because it’s so assertive and so sure of itself,” says Koeppl. “But you really need the experts to evaluate that result.”

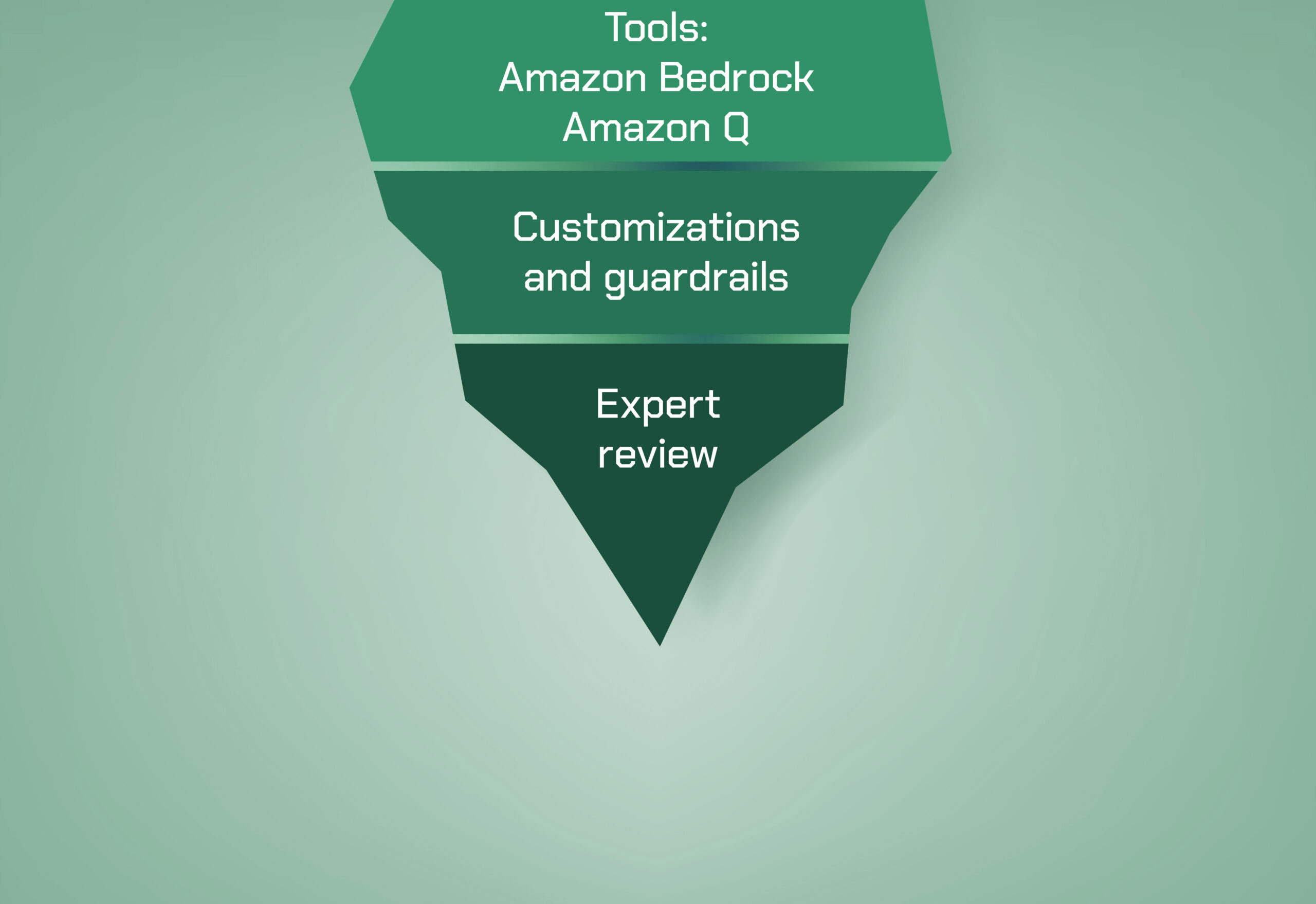
All of this may seem daunting, which again is why experts recommend proceeding incrementally. And there are solutions that can make it easier for organizations to successfully implement generative AI. Amazon Bedrock, for example, offers a full suite of tools to enable advanced architectures like RAG frameworks – in which LLM output is informed by a trusted knowledge base – and guardrails that help ensure safety.
Guardrails for Amazon Bedrock also provides additional customizable safeguards on top of native protections offered by LLMs and blocks as much as 85 percent more harmful content and filters over 75 percent of hallucinated responses for RAG and summarization workloads.
Amazon Q Business, meanwhile, easily and securely connects to over 40 commonly used business tools, such as wikis, intranets, email, customer relationship management apps and more. Users can simply point Amazon Q at their enterprise data and code repositories, and it will search all their data, summarize it logically, analyze trends, generate insights and engage in dialogue with end users about the data.
Amid all of the technical considerations around generative AI, it’s important that organizations are able to see the forest, not just the trees. That is, they must not lose sight of the business case for the technology and what they are trying to accomplish. When starting out, it’s best for companies to begin with smaller, focused use cases. “It starts with the business strategy, and the customer’s problem. Don’t start with the solution,” says Koeppl.
To get it right, Godden advises clients to start small and go from there. “You don’t have to boil the ocean,” he says. “Let value be your guide … you don’t have to transform your entire enterprise today.” Organizations can proceed by incrementally building a robust, enterprise-grade data foundation. Proof-of-concept models that leverage this data can be spun up quickly to validate an idea and expanded gradually. Eventually, organizations can evolve this foundation to allow AI services to run at scale for thousands or even millions of users.